
Unlocking the Power of Data: Revolutionizing Pest and Disease Management for Sustainable Agriculture
Imagine the future of agriculture is right in front of us – and it’s powered by data. The Use Case 3 team “Streamlining pest and disease data to advance integrated pest management” has set an ambitious goal: to collect, connect, and harmonize pest and disease data to revolutionize how we manage them.
Why does this matter? The use of pesticides needs to be cut by 50% until 2030, but how can we achieve this without risking crop yields? The answer lies in data, and we’re on the verge of unlocking its full potential. Keep reading to discover how this digital transformation will shape the future of sustainable farming!
Contents of this page:
UC 3 Partners:

Motivation
Boosting IPM with a FAIR data revolution
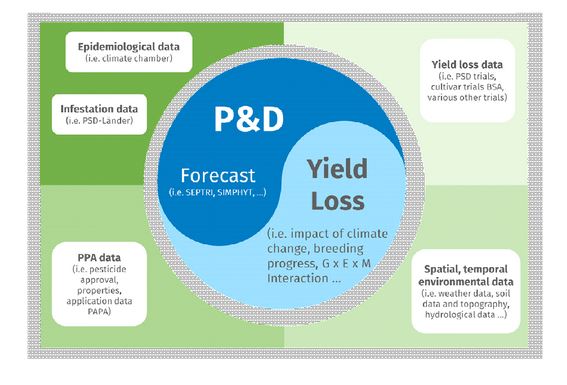
Wanted: pest & disease data
In the realm of agriculture, data is the treasure we seek. The Use Case (UC) 3 Team “Streamlining pest and disease data to advance integrated pest management” is on a mission to harness these data treasures to improve the way we manage pests and diseases. At its core, crop protection strives to minimize the yield losses caused by pests and diseases. Yet, the increasing scientific and public concern over pesticide use has led to a significant shift in strategy. The European Union’s farm-to-fork strategy aims to cut pesticide use by 50% by 2030, marking a major step towards sustainable agriculture.
Integrated Pest Management (IPM) is a key player in this transformation. IPM aims to reduce pesticide use and its environmental impact by leveraging diverse crop management options, including advanced decision support systems. By doing so, IPM helps to balance the trade-offs between crop protection and environmental sustainability.
Missing: pest & disease data
However, one major hurdle in the path of effective IPM is the challenge of managing and utilizing pest and disease data. The findability, standardization, accessibility, and integration of IPM-related data, models, and decision support systems are often lacking. The data, which primarily come from yield-loss trials, epidemiological experiments, and pest and disease infestation records, face several obstacles:
1. Experimental Heterogenety
Variations in experimental design (e.g. control treatments) and disease assessment procedures (timing, scale, sample size) complicate data comparison and integration.
2. Data Accessibility
Insufficient information on the existence and accessibility of specific pest and disease data in Germany.
3. Model Integration
Existing models for IPM decision support are not integrated, lacking a comprehensive approach that considers potential yield loss and environmental risks of pesticide application.
By addressing these data management challenges, we can unlock the full potential of IPM. This will not only enhance crop protection strategies but also contribute significantly to sustainable farming practices. The revolution in Research Data Management (RDM) for pest and disease data promises to bring a new era of precision and efficiency to agriculture, making it both environmentally friendly and highly productive.
Stay tuned as we dive deeper into the ways we can turn data into actionable insights and transform the future of pest management.
Preliminary achievements
Drawing a map of the IPM data landscape
As we progress in our mission to revolutionize pest and disease (P&D) data management, we’re thrilled to share some preliminary achievements and ongoing efforts within Use Case 3 (UC3).
First and foremost, we’ve made significant strides in compiling an inventory of P&D data, a crucial step toward advancing P&D research. However, the task hasn’t been without its challenges; the data landscape is highly fragmented among various stakeholders including research institutions, universities ect. as well as governmental authorities, making assembling the inventory no small feat. Nevertheless, this endeavor marks a substantial leap forward in consolidating P&D research resources.
Navigating through the IPM dataverse
Securing data from diverse sources has proven to be another obstacle. Many institutions use PIAF (1) to handle plant-based and experiment, organize and store their data locally. Unfortunately, several “versions” of PIAF-kind databases exist across the P&D data landscape and no connections across databases are established. That means today data access is restricted and data sharing is not possible. To tackle this challenge, we’ve collaborated with PIAF developers to develop scripts capable of harvesting data from disparate database instances. Furthermore, we identified a potential repository where a central database for P&D data can be hosted in the future.
(1) PIAF (Planungs-, Informations- und Auswertungssystem für das Versuchswesen in Landwirtschaft, Weinbau, Gartenbau und Agrarforschung) is a database-based experiment program that covers all aspects of the experimental process, from planning and data collection to statistical analysis. Its versatile structure allows for the management of various types of experiments within the same program, with the ability to customize displayed content. This enables the representation of single or multi-factorial experiments, accommodating factors such as variety, fertilization, plant protection, or crop rotation. PIAF supports a wide range of crops including field crops, wine, vegetables.
Harmonize IPM data from different galaxies
Additionally, recent efforts have involved developing and harmonizing (database) data models to capture P&D data across institutions and databases. The close collaboration with the data stewards from the Data Steward Service Center (DSSC) was and remains highly valuable to align them to existing data models for long-term experiments which are part of the Bonares repository data infrastructure already for instance. The aim is, when the database is ready we pull data from the differences PIAF instances and import there data into the centralized system, make metadata accessible across institutions and facilitate data sharing.
Collaborative efforts with BonaRes staff and data stewards (DSSC) allow to harmonize data models, paving the way for enhanced interoperability and data utilization. Additionally, synergies with UC6 and UC2 present exciting opportunities for use case collaboration across disciplines making valuable contributions to the harmonization efforts across disciplines.
Boosting data quality with data management
This is also of particular importance on another major FAIRagro topic “data quality”. Within the first joint workshop dedicated to the topic “Data Quality for Data Analytics in Agrosystem Science (DQ4DA)“, UC 3 contributed their requirements and experiences relevant for the FAIRagro developments of central services and infrastructure. The outcomes of the joint Workshop and indications for the FAIRagro are summirized in the workshop report: „FAIRagro Workshop on Data Quality for Data Analytics in Agrosystem Science (DQ4DA)“ .
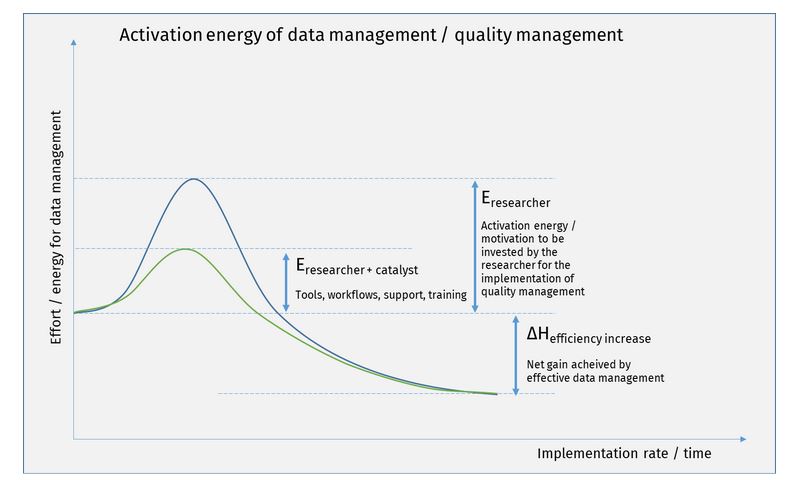
During the second FAIRagro data quality workshop in Braunschweig in June 2024 it became, once more, apparent how important formalization and categorization of processes are. The data quality challenges cover the entire array from planning, data acquisition over storage, processing, publication and, eventually FAIR use.
In the following main thoughts and key findings from the data quality workshop are summarized:
- Definition and integration of processes are prerequisite for smooth data.
- Data management plans are often considered a “tour of duty”
- Compliance with DMPs is not checked
- It would be helpful to rethink RDMO as an integrated tool, which provides a DMP as a side effect, while focusing on the creation of data management tools, such as:
- Standardized folder structure for project management (rooted in the institutional data management strategy)
- Implementation of ARCs (annotated research containers) to ensure rich metadata description, machine readability and data consistency
- Production of standardized templates for data acquisition and processing, including statistical methods for data quality evaluation
- Definition of core data sets for data use cases ensures improved reusabilty of data.
- Research questions and, consequentially, experimental designs within agrosystems research differ widely. So do data types and formats. From a data management perspective, this is challenging and complex task.
- There must be good reasons for researchers to produce extra data in order to fulfil a core dataset requirement.
- Provision of downstream processing tools could be a good way to nudge people into a more formal/standardized behavior.
- The main focus should be on the creation of sound, standardized and machine readable metadata:
- Data Provenance is of utmost importance
- Declaration of units
- System boundaries
- Statistical information
- Technical data (e.g. on machinery used for data acquisition and processing)
- Spatio-temporal data
- Information on code and data processing
- Data resolution / level of aggregation is important for data quality and comparability – whose impacts are sometimes counter-intuitive for the user.
- Interoperability is a major issue with regards to data integration and quality.
- In many, if not most cases, data and more specifically geodata from repositories cannot easily integrated in workflows, since (geo-)data is often
- too heterogenous
- poorly described
- subject to constant change
- vast in volume and difficult to host
- In many, if not most cases, data and more specifically geodata from repositories cannot easily integrated in workflows, since (geo-)data is often
- Lack of overview makes it difficult to judge data quality.
- Geodashboard is a cockpit that can help to track and visualize data quality timely
- Provo and Provr are R-Scripts that automatically extract metadata information and provenance information from data sets.
- Lack of coherent use of standards and standard routines.
- There are a lot of guidelines and best practices for all kinds of methods, assays and experimental designs.
- There are numerous metadata standards established, ranging from narrow-focused, discipline-specific ontologies to generic, discipline-overarching ones.
- Practical implementation of standard routines or standardized metadata requires a formal, documented process, ensuring consistency and unambiguity.
- It might be helpful to increase awareness over standards by including the information in an improved RDMO tool (🡪 1) or as a separate experimental-designer web-tool
- Descriptive representation of knowledge is often insufficient to nudge people into the implementation.
- Hands-on experience and support with easy-to-use and easy-to-customize tools would be suitable to foster data and metadata quality.
All details are published in the workshop report “FAIRagro Workshop: Geodata quality in the application of agricultural system data“ .
Next steps and possible points of connection
Moving IPM data harmonization and presentation to the next level
Together with the other Use Case we exploit opportunities to use Annotated Research Contexts (ARCs) as structured representations of research data and metadata, serving as lightweight units for storing, describing, and managing data within the FAIRagro infrastructure. This sounds complex, but the features which derive from using this “technology” will definitely make a difference and prepare IP research to address future challenges.
This is great example how the collaboration across agriculture and RDM experts within FAIRagro really can make the difference and enhance research practises. You are keen to know more about it, engage with FAIRgro colleagues and experts or test novel technology or tools? Get in touch with us or visit one of the future FAIRgro events.
Looking ahead, we’re planning a workshop with data holders including governmental authorities to further facilitate collaboration and data sharing committed to fostering meaningful connections within the research community to unlock the full potential of the hidden data treasures relevant for innovative IPM.
Find some more details about the preliminary results and future work plan of the Use Case 3 team in the overview of the poster and get in touch with: Streamlining Pest and Disease data UC3 Action 2: Towards improved FAIRness.
von Anne Sennhenn und Stefan Kühnel