
Die Macht der Daten freisetzen: Revolutionierung des Schädlings- und Krankheitsmanagements für eine nachhaltige Landwirtschaft
Stellen Sie sich vor, die Zukunft der Landwirtschaft liegt direkt vor uns – und sie wird von Daten angetrieben. Das Team des Use Case 3 „Streamlining pest and disease data to advance integrated pest management“ hat sich ein ehrgeiziges Ziel gesetzt: die Sammlung, Vernetzung und Harmonisierung von Daten über Schädlinge und Krankheiten, um die Art und Weise, wie wir sie verwalten, zu revolutionieren.
Warum ist das wichtig? Der Einsatz von Pestiziden muss bis 2030 um 50 % reduziert werden, aber wie können wir das erreichen, ohne die Ernteerträge zu gefährden? Die Antwort liegt in den Daten, und wir stehen kurz davor, ihr volles Potenzial zu erschließen. Lesen Sie weiter, um zu erfahren, wie dieser digitale Wandel die Zukunft der nachhaltigen Landwirtschaft gestalten wird!
Inhalt dieser Seite:
UC 3 Partner:

Motivation
IPM mit einer FAIRen Datenrevolution vorantreiben
Gesucht: Daten zu Schädlingen und Krankheiten
Im Bereich der Landwirtschaft sind Daten der Schatz, den wir suchen. Das Use Case (UC) 3 Team „Streamlining pest and disease data to advance integrated pest management“ hat sich zum Ziel gesetzt, diese Datenschätze zu heben, um die Art und Weise zu verbessern, wie wir mit Schädlingen und Krankheiten umgehen. Im Kern zielt der Pflanzenschutz darauf ab, die durch Schädlinge und Krankheiten verursachten Ertragsverluste zu minimieren. Die zunehmende wissenschaftliche und öffentliche Besorgnis über den Einsatz von Pestiziden hat jedoch zu einem deutlichen Strategiewechsel geführt. Die Strategie der Europäischen Union „vom Erzeuger zum Verbraucher“ zielt darauf ab, den Pestizideinsatz bis 2030 um 50 % zu senken, was einen wichtigen Schritt in Richtung einer nachhaltigen Landwirtschaft darstellt.
Was fehlt? Daten zu Schädlingen und Krankheiten
Eine große Hürde auf dem Weg zu einer effektiven IPM ist jedoch die Verwaltung und Nutzung von Schädlings- und Krankheitsdaten. Es mangelt oft an der Auffindbarkeit, Standardisierung, Zugänglichkeit und Integration von IPM-bezogenen Daten, Modellen und Entscheidungshilfesystemen. Die Daten, die in erster Linie aus Ertragsverlustversuchen, epidemiologischen Experimenten und Aufzeichnungen über Schädlings- und Krankheitsbefall stammen, sind mit mehreren Hindernissen konfrontiert:
1. Experimentelle Heterogenität
Unterschiede in der Versuchsplanung (z. B. Kontrollbehandlungen) und den Krankheitsbewertungsverfahren (Zeitpunkt, Umfang, Stichprobengröße) erschweren den Vergleich und die Integration der Daten.
2. Zugänglichkeit der Daten
Unzureichende Informationen über das Vorhandensein und die Zugänglichkeit von spezifischen Schädlings- und Krankheitsdaten in Deutschland.
3. Modell-Integration
Bestehende Modelle zur Unterstützung von IPM-Entscheidungen sind nicht integriert, und es fehlt ein umfassender Ansatz, der potenzielle Ertragsverluste und Umweltrisiken des Pestizideinsatzes berücksichtigt.
Indem wir diese Herausforderungen des Datenmanagements angehen, können wir das volle Potenzial des IPM ausschöpfen. Dies wird nicht nur die Pflanzenschutzstrategien verbessern, sondern auch einen wichtigen Beitrag zu nachhaltigen landwirtschaftlichen Praktiken leisten. Die Revolution im Forschungsdatenmanagement (RDM) für Schädlings- und Krankheitsdaten verspricht eine neue Ära der Präzision und Effizienz in der Landwirtschaft, die sowohl umweltfreundlich als auch hochproduktiv sein wird.
Bleiben Sie dran, wenn wir gleich tiefer in die Möglichkeiten eintauchen, wie wir Daten in umsetzbare Erkenntnisse verwandeln und die Zukunft des Pflanzenschutzes verändern können.
Erste Ergebnisse und Erfolge
Zeichnen einer Karte der IPM-Datenlandschaft
Im Rahmen unserer Mission, die Verwaltung von Schädlings- und Krankheitsdaten (P&D) zu revolutionieren, freuen wir uns über einige vorläufige Erfolge innerhalb von Use Case 3 (UC3).
In erster Linie haben wir große Fortschritte bei der Zusammenstellung eines Inventars von P&D-Daten gemacht, ein entscheidender Schritt, um die P&D-Forschung voranzubringen. Die Aufgabe war jedoch nicht ohne Herausforderungen; die Datenlandschaft ist stark fragmentiert und auf verschiedene Akteure wie Forschungseinrichtungen, Universitäten usw. sowie Regierungsbehörden verteilt, so dass die Zusammenstellung des Inventars keine leichte Aufgabe ist. Nichtsdestotrotz stellt dieses Unterfangen einen erheblichen Fortschritt bei der Konsolidierung der Forschungsressourcen im Bereich Pflanzenschutz dar.
Navigieren durch das IPM-Datenmeer
Die Beschaffung von Daten aus verschiedenen Quellen hat sich als weiteres Hindernis erwiesen. Viele Institutionen nutzen PIAF (1) , um ihre Daten lokal zu verwalten, zu organisieren und zu speichern. Leider gibt es in der gesamten IPM-Datenlandschaft mehrere „Versionen“ von PIAF-ähnlichen Datenbanken, und es werden keine datenbankübergreifenden Verbindungen hergestellt. Das bedeutet, dass der Zugang zu den Daten heute eingeschränkt ist und eine gemeinsame Nutzung der Daten nicht möglich ist. Um diese Herausforderung zu bewältigen, haben wir in Zusammenarbeit mit den PIAF-Entwicklern Skripte entwickelt, mit denen Daten aus unterschiedlichen Datenbankinstanzen abgerufen werden können. Darüber hinaus haben wir ein potenzielles Repository identifiziert, in dem in Zukunft eine zentrale Datenbank für P&D-Daten untergebracht werden kann.
(1) PIAF (Planungs-, Informations- und Auswertungssystem für das Versuchswesen in Landwirtschaft, Weinbau, Gartenbau und Agrarforschung) ist ein datenbankbasiertes Versuchsprogramm, das alle Aspekte des Versuchsprozesses abdeckt, von der Planung über die Datenerfassung bis hin zur statistischen Auswertung. Seine vielseitige Struktur erlaubt die Verwaltung verschiedener Versuchstypen innerhalb desselben Programms mit der Möglichkeit, die angezeigten Inhalte individuell anzupassen. Dies ermöglicht die Darstellung von ein- oder mehrfaktoriellen Versuchen, die Faktoren wie Sorte, Düngung, Pflanzenschutz oder Fruchtfolge berücksichtigen. PIAF unterstützt eine breite Palette von Kulturen, einschließlich Feldfrüchten, Wein und Gemüse.
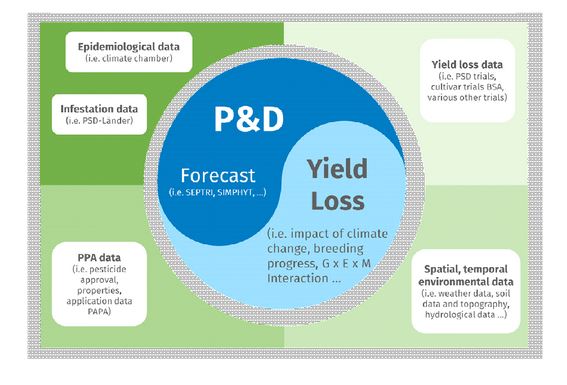
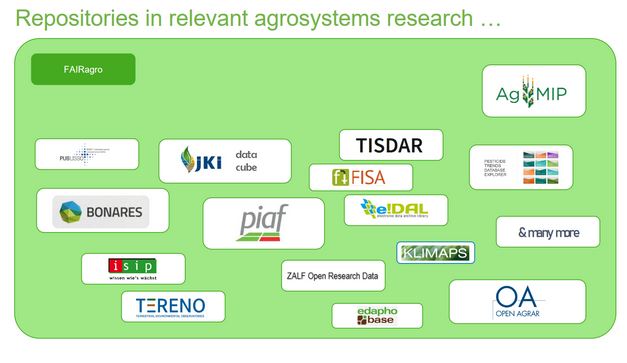
Harmonisierung von IPM-Daten aus verschiedenen Galaxien
Darüber hinaus wurden in jüngster Zeit (Datenbank-)Datenmodelle entwickelt und harmonisiert, um P&D-Daten institutions- und datenbankübergreifend zu erfassen. Die enge Zusammenarbeit mit den Datenverwaltern des Data Steward Service Center (DSSC) war und ist sehr wertvoll, um sie an bestehende Datenmodelle für Langzeitexperimente anzugleichen, die beispielsweise bereits Teil der Dateninfrastruktur des Bonares-Repository sind. Ziel ist es, wenn die Datenbank fertig ist, die Daten aus den verschiedenen PIAF-Instanzen in das zentrale System zu importieren, die Metadaten institutionsübergreifend zugänglich zu machen und die gemeinsame Nutzung von Daten zu erleichtern.
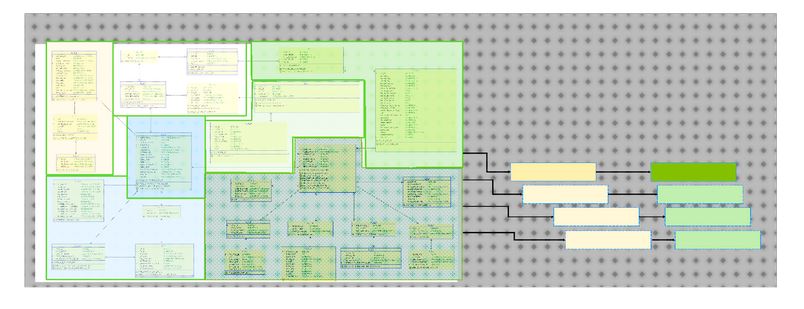
Die Zusammenarbeit mit BonaRes-Mitarbeitern und Datenverwaltern (DSSC) ermöglicht die Harmonisierung von Datenmodellen und ebnet den Weg für eine verbesserte Interoperabilität und Datennutzung. Darüber hinaus ergeben sich durch die Synergien mit UC6 und UC2 interessante Möglichkeiten für die interdisziplinäre Zusammenarbeit bei Anwendungsfällen, die einen wertvollen Beitrag zu den fachübergreifenden Harmonisierungsbemühungen leisten.
Steigerung der Datenqualität durch Datenmanagement
Dies ist auch bei einem anderen wichtigen FAIRagro-Thema, der Datenqualität, von besonderer Bedeutung. Im Rahmen des ersten gemeinsamen Workshops zum Thema „Data Quality for Data Analytics in Agrosystem Science (DQ4DA)“ hat UC 3 ihre Anforderungen und Erfahrungen eingebracht, die für die FAIRagro-Entwicklungen zentraler Dienste und Infrastrukturen relevant sind. Die Ergebnisse des gemeinsamen Workshops und Hinweise für FAIRagro sind im Workshopbericht „FAIRagro Workshop on Data Quality for Data Analytics in Agrosystem Science (DQ4DA)“ zusammengefasst.
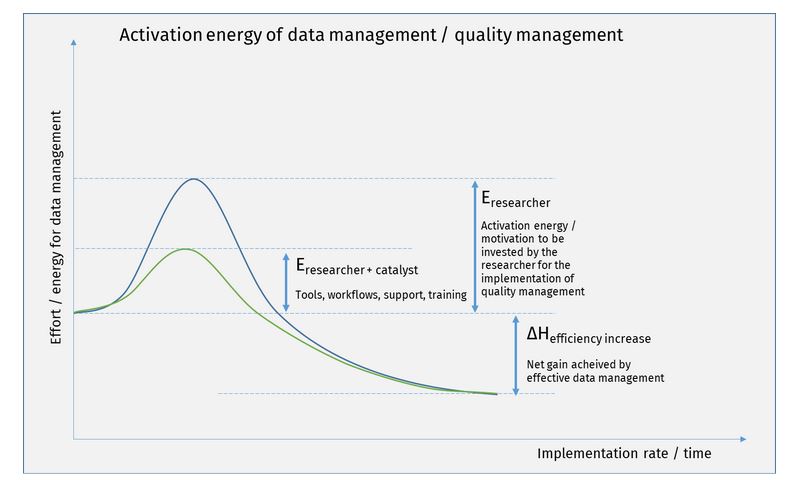
Beim zweiten FAIRagro-Datenqualitätsworkshop in Braunschweig im Juni 2024 wurde einmal mehr deutlich, wie wichtig die Formalisierung und Kategorisierung von Prozessen ist. Die Herausforderungen an die Datenqualität erstrecken sich über den gesamten Bereich von der Planung, Datenerfassung über die Speicherung, Verarbeitung, Veröffentlichung und schließlich FAIR-Nutzung.
Im Folgenden sind die wichtigsten Gedanken und Erkenntnisse aus dem Datenqualitätsworkshop zusammengefasst:
- Definition und Integration von Prozessen sind Voraussetzung für reibungslose Daten.
- Datenmanagementpläne werden oft als „Dienstreise“ betrachtet
- Die Einhaltung der DMP wird nicht kontrolliert
- Es wäre hilfreich, RDMO als integriertes Werkzeug zu begreifen, das als Nebeneffekt ein DMP bereitstellt, wobei der Schwerpunkt auf der Erstellung von Datenmanagement-Tools liegt, wie z.B:
- Standardisierte Ordnerstruktur für das Projektmanagement (verankert in der institutionellen Datenmanagementstrategie)
- Implementierung von ARCs (annotated research containers) zur Sicherstellung einer umfassenden Metadatenbeschreibung, maschineller Lesbarkeit und Datenkonsistenz
- Erstellung von standardisierten Vorlagen für die Datenerfassung und -verarbeitung, einschließlich statistischer Methoden zur Bewertung der Datenqualität
- Definition von Kerndatensätzen für Datenanwendungsfälle zur Gewährleistung einer verbesserten Wiederverwendbarkeit von Daten.
- Die Forschungsfragen und folglich auch die Versuchspläne innerhalb der Agrarsystemforschung sind sehr unterschiedlich. Dies gilt auch für die Datentypen und -formate. Aus Sicht des Datenmanagements ist dies eine anspruchsvolle und komplexe Aufgabe.
- Es muss gute Gründe dafür geben, dass Forscher zusätzliche Daten produzieren, um die Anforderungen an einen Kerndatensatz zu erfüllen.
- Die Bereitstellung von Werkzeugen für die nachgelagerte Verarbeitung könnte ein guter Weg sein, um die Menschen zu einem formaleren/standardisierten Verhalten zu bewegen.
- Das Hauptaugenmerk sollte auf der Erstellung von soliden, standardisierten und maschinenlesbaren Metadaten liegen:
- Datenprovenienz ist von größter Bedeutung
- Deklaration von Einheiten
- Systemgrenzen
- Statistische Informationen
- Technische Daten (z.B. über die zur Datenerfassung und -verarbeitung eingesetzten Maschinen)
- Räumlich-zeitliche Daten
- Informationen über Code und Datenverarbeitung
- Die Datenauflösung/der Aggregationsgrad ist wichtig für die Datenqualität und die Vergleichbarkeit – deren Auswirkungen für den Nutzer manchmal kontraintuitiv sind.
- Interoperabilität ist ein wichtiges Thema im Hinblick auf die Datenintegration und -qualität
- In vielen, wenn nicht sogar den meisten Fällen können Daten und insbesondere Geodaten aus Repositories nicht einfach in Arbeitsabläufe integriert werden, da (Geo-)Daten oft
- zu heterogen
- unzureichend beschrieben sind
- einem ständigen Wandel unterliegen
- sehr umfangreich und schwer zu hosten sind
- In vielen, wenn nicht sogar den meisten Fällen können Daten und insbesondere Geodaten aus Repositories nicht einfach in Arbeitsabläufe integriert werden, da (Geo-)Daten oft
- Mangelnder Überblick erschwert das Jonglieren mit der Datenqualität:
- Geodashboard ist ein Cockpit, das helfen kann, die Datenqualität zeitnah zu verfolgen und zu visualisieren
- Provo und Provr sind R-Skripte, die automatisch Metadaten und Herkunftsinformationen aus Datensätzen extrahieren.
- Fehlende kohärente Verwendung von Standards und Standardroutinen:
- Es gibt eine Vielzahl von Richtlinien und Best Practices für alle Arten von Methoden, Assays und Versuchsplänen.
- Es gibt zahlreiche Metadatenstandards, die von eng fokussierten, disziplinspezifischen Ontologien bis hin zu generischen, disziplinübergreifenden Ontologien reichen.
- Die praktische Umsetzung von Standardroutinen oder standardisierten Metadaten erfordert einen formalen, dokumentierten Prozess, der Konsistenz und Eindeutigkeit gewährleistet.
- Es könnte hilfreich sein, das Bewusstsein für Standards zu schärfen, indem die Informationen in ein verbessertes RDMO-Tool (siehe 1.) oder in ein separates Web-Tool für Versuchsplaner aufgenommen werden
- Die beschreibende Darstellung von Wissen reicht oft nicht aus, um die Menschen zur Umsetzung zu bewegen.
- Praktische Erfahrungen und Unterstützung mit einfach zu bedienenden und leicht anzupassenden Werkzeugen wären geeignet, um die Qualität von Daten und Metadaten zu fördern
Alle Details sind im Workshop-Bericht „FAIRagro Workshop: Geodatenqualität in der Anwendung von Agrarsystemdaten“ nachzulesen.
Nächste Schritte und mögliche Anknüpfungspunkte
Das Heben von IPM-Datenharmonisierung und -präsentation auf die nächste Stufe
Zusammen mit anderen Use Cases nutzen wir Möglichkeiten zur Verwendung von Annotated Research Contexts (ARCs) als strukturierte Darstellungen von Forschungsdaten und Metadaten, die als leichtgewichtige Einheiten für die Speicherung, Beschreibung und Verwaltung von Daten innerhalb der FAIRagro-Infrastruktur dienen. Das hört sich kompliziert an, aber die Funktionen, die sich aus der Verwendung dieser „Technologie“ ergeben, werden definitiv einen Unterschied machen und die IP-Forschung auf künftige Herausforderungen vorbereiten.
Dies ist ein großartiges Beispiel dafür, wie die Zusammenarbeit zwischen Landwirtschafts- und RDM-Experten innerhalb von FAIRagro wirklich den Unterschied ausmachen und die Forschungspraxis verbessern kann. Sie möchten mehr darüber erfahren, sich mit FAIRagro-Kollegen und -Experten austauschen oder neue Technologien und Instrumente testen? Setzen Sie sich mit uns in Verbindung oder besuchen Sie eine der zukünftigen FAIRgro-Veranstaltungen.
Mit Blick auf die Zukunft planen wir einen Workshop mit Dateninhabern, einschließlich Regierungsbehörden, um die Zusammenarbeit und den Datenaustausch weiter zu erleichtern und sinnvolle Verbindungen innerhalb der Forschungsgemeinschaft zu fördern, um das volle Potenzial der verborgenen Datenschätze zu erschließen, die für eine innovative IPM relevant sind.
Weitere Einzelheiten über die vorläufigen Ergebnisse und den künftigen Arbeitsplan des Use Case 3-Teams finden Sie in der Übersicht des Posters und nehmen Sie Kontakt mit uns auf: Streamlining Pest and Disease data UC3 Action 2: Towards improved FAIRness.
von Anne Sennhenn und Stefan Kühnel